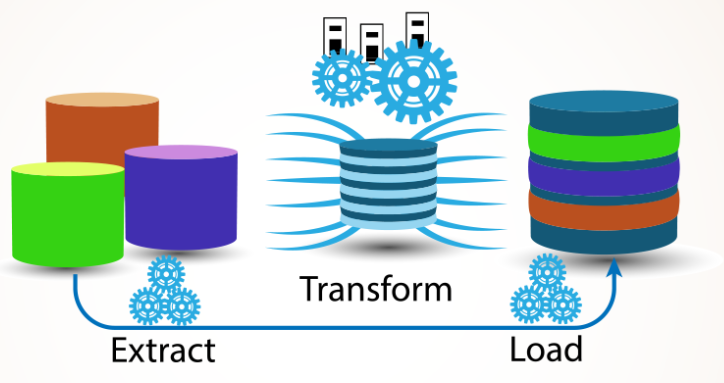
Data integration is a crucial task for any data-driven organization today.
With data coming from many sources and going to many destinations, having a scalable and maintainable ETL solution is key.
This is where Azure Data Factory and its mapping data flows really shine.
In this article, we’ll walk through how to leverage ETL with Azure Data Factory and mapping data flows to develop powerful extract, transform, and load (ETL) pipelines for data lakes and data warehouses. We’ll cover key features, provide examples, and share best practices based on real-world experience.
The ETL Challenge
First, let’s discuss why ETL is so challenging. Typically, data comes from many upstream sources and applications in different formats.
It then needs to be validated, cleansed, transformed, and aggregated before loading into a destination data store.
This requires complex logic and data mappings that can quickly become unmanageable tangles of code.
It’s also resource-intensive, requiring significant computing power. As data volumes and sources grow, traditional ETL can buckle under the strain.
Enter Azure Data Factory
Azure Data Factory provides a managed service to create and schedule data integration workflows at scale.
It can connect to virtually any data source, including databases, cloud applications, and file shares.
Key capabilities include:
- Connectivity to over 90 data sources with additional connectors available
- Scalable orchestration to process terabytes of data on demand or on schedule
- Integration with Azure services like Data Lake Storage, SQL Data Warehouse, and others
- Monitoring tools to track pipeline runs and failures
- Management of pipelines as code for version control and collaboration
Introducing Mapping Data Flows
While Azure Data Factory provides robust orchestration, transforming the data itself still requires writing code in activities like Databricks notebooks.
Mapping data flows eliminates the need for coding by providing a visual data transformation interface.
You simply drag and drop data source and sink nodes onto a canvas and connect them with transformation steps.
Here are some key features of mapping data flows:
- Code-free visual authoring of data transformations
- Support for over 70 native transformations like join, filter, select, and aggregate
- Integration with Data Factory pipelines for orchestration
- Executes data flows at scale on Azure Databricks clusters
- Monitoring of data flow runs with metrics and lineage
ETL for Data Lakes Example
Let’s walk through a common ETL scenario for a data lake using Azure Data Factory and mapping data flows.
First, we’ll ingest raw CSV files from an on-premises system into Azure Data Lake Storage using a copy activity.
This raw data will be staged for further processing.
Next, we’ll leverage a mapping data flow to:
- Read the staged CSV files
- Apply schema and validate the data
- Filter out any unwanted records
- Enrich the data by joining to a dimension table
- Aggregate metrics and totals
- Write the transformed data to our Azure Synapse Analytics data warehouse
By using Azure Data Factory and mapping data flows in this way, we can develop reliable and scalable ETL pipelines for our data lake without writing any code!

Best Practices
Here are some key best practices to follow when using Data Factory and mapping data flows for ETL:
- Store unmodified raw data in the lake and transform downstream
- Develop data flows iteratively with test data and verify logic
- Parameterize data flows to make them reusable across pipelines
- Monitor data flow runs to identify bottlenecks and optimize
- Implement CI/CD to promote flows across environments
- Add metadata and meaningful naming at each step
Supercharge Your Data Integration with Azure
In summary, Azure Data Factory and mapping data flow provide a powerful code-free environment to develop scalable ETL pipelines.
Robust pre-built transformations, visual authoring, and managed orchestration let you focus on the business logic rather than coding. If you’re struggling to keep up with growing data volumes and complexity, it’s time to supercharge your data integration process with Azure. Reach out if you need help getting started!